고정 헤더 영역
상세 컨텐츠
본문
데이터 모델의 종류 중 조건부 모델과 생성 모델에 대해 Key concept만 먼저 되짚어 보겠습니다.
조건부 모델(Discriminative Models) :

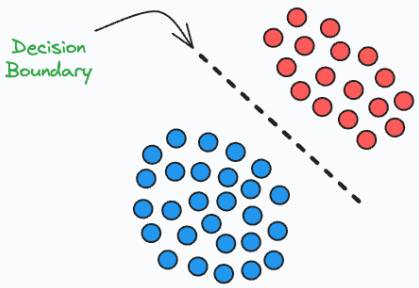
- 서로 다른 class를 구분, 구별할 수 있는 경계(Decision Boundaries)를 학습한다.
- 조건부 확률 P(Y|X)를 최대화 한다.
- 주어진 입력 X에 대해 정답값(Label)Y의 확률을 최대화 - 분류 작업(Classification Tasks)를 하기 위한 방법 중 하나.
생성 모델(Generative Models) :
- 결합 확률 P(X,Y)를 최대화 한다.
- Class의 조건부 분포 P(X|Y)를 학습한다.
- 일반적인 분류 방법은 아니지만, 분류를 수행할 수 있어서 활용하는 경우가 있다.
이제 조건부 모델에 대해 조금 더 알아보겠습니다.
조건부 모델의 요점은 함수 f (vector X 와 label Y의 조합) 를 직접 학습한다는 것입니다.

위의 그림처럼 조건부 모델은 일반적으로 두 개의 큰 틀로 나누어 볼 수 있습니다.
- 확률 모델 Probabilistic Models
- 직접 연결 모델 Direct Labeling Models
Probabilistic Models

- 주어진 데이터에 대한 각 카테고리의 확률 분포를 제공.
- 입력된 데이터에 대한 불확실성을 직접적으로 표현하며, 그 확률적인 특성을 이용해 최종 판단에 도움을 줌.
이름에서 알 수 있듯, Probabilistic Models 은 각 Class별로 구별 될 확률을 계산합니다.
확률에 대한 계산은 사전 학습된 Class Probabilities P(Y|X)에 대해 진행됩니다.
즉 분류하고자 하는 Case를 기존 학습된 데이터 중 가장 근접한 Class가 무엇인지 계산하여 나타냅니다.
결과적으로, Probabilistic Model은 특정 Class를 이용한 사전 학습된 규칙에 의해 새로운 데이터의 Label을 예측합니다.
이와 같은 방법은 불확실성(Uncertainty)이 문제에 매우 중요한 부분으로 작용할 때 적합합니다.
- 불확실성이 중요한 문제 : Logistic regression, Neural network, CRFs
로지스틱 회귀 (Logistic Regression) - 선형 회귀의 확장으로, 로지스틱 함수를 사용하여 이진 분류 문제에 대한 확률을 예측하는데 사용된다. 또한, 다중 클래스 분류 문제에도 적용될 수 있다. 로지스틱 회귀의 출력은 확률(Probability)로, 이를 특정 임계값과 비교하여 Class label을 결정한다.
Labeling Models

- 주어진 데이터를 특정 카테고리로 빠르게 분류하는데 중점을 둠.
- 어떤 기준이나 알고리즘을 사용하더라도 최종적으로 하나의 결과값만 제공.
Probabilistic Model과 달리 Labeling Model(또는 무분포 분류기)은 확률적 추정을 하지 않고 Class Label을 직접 예측합니다.
결과적으로 Labeling Model의 예측은 어느 정도의 신뢰도를 나타내지 않습니다. 바로 예측 결과를 알려줍니다.
이로 인해 모델 예측의 불확실성이 중요한 경우에는 적합하지 않습니다.
- 불확실성에 대한 중요도가 낮은 문제 : Random forests, kNN, Decision trees
| Random Forest - 분류 및 회귀 작업에 사용되는 앙상블 학습 방법 중 하나. 앙상블 학습은 여러 개의 모델을 조합하여 하나의 강력한 모델을 만드는 방법을 의미. 여러개의 Decision Tree(의사 결정 나무)를 학습하고, 그 Tree들의 예측을 조합하여 최종 결과 값을 도출하는 방법. |
Labeling 예측 결과를 제공하는 위와 같은 모델들도 어떤 방식으로든 확률을 출력할 수는 있습니다.
예를 들어, Sklearn의 Decision tree classifier는 predict_proba() 메서드를 제공하며, 아래와 같이 표시됩니다:

처음에는 약간 직관적이지 않게 보일 수 있습니다.
이 경우, 모델은 leaf node 내의 training class label의 비율을 보고 class probability 출력합니다.

다시 말해서, Test instance가 최종 분류를 위해 특정 leaf node에 도달한다고 가정해보죠.
Model은 해당 Leaf node 내의 Training class label의 비율로 확률을 계산할 것입니다.

이러한 조작은 예측에서의 "진정한" 불확실성을 반영하지 않습니다.
이는 동일한 leaf node에 속하는 모든 예측에 대한 불확실성이 동일하기 때문입니다.
따라서 불확실성이 매우 중요할 때는 확률적 분류기를 선택하는 것이 현명합니다.





댓글 영역